This is a 100% practical course, and most of the theoretical introductions to compiler are left out. In this unit we would discuss the tokenizer which generate the tokens. The tokenizer converts a high level program to distinct units called tokens. Tokens are the smallest unit of a written program. tokenizer.cpp will be broken down into subunits.
1. Opening and closing the program file.
2. Defining list of acceptable tokens.
3. Scanning.
4. Generating tokens.
4. Error check.
1. Opening and closing the program file Hint: the line numbers denote the position of each code on the tokenizer.cpp file, this particular section is kept at the bottom of the file. < br/>
We start by writing code to open the .cpp program file, reading from it and closing it.
To work with any .cpp file, we need to able to access the name of the file. One way is through the command line. So to compile any file we need to pass the name as an argument in our main function. So to compile we write compiler.exe compilefile.cpp and argument 1 in the main function becomes compilefile.cpp.
Next, using fopen, we would open the file and catch error when its null.
We need to find the size of the file , then create of char* buffer of same size and copy the contents of our .cpp files into it for processing. To do this, we use fseek to navigate to the end of the file, then using ftell we could tell the size at that point and finally create a buffer and allocate memory of the same size to it. After getting the size of the file, we need to take our pointer back to the beginning of the file.
Finally, we check if the char* buffer was created successfully, then using fread() we would copy the content of our .cpp file into the buffer created. We pass the buffer to the scanner function which process the codes and lastly we delete the buffer and close the file.
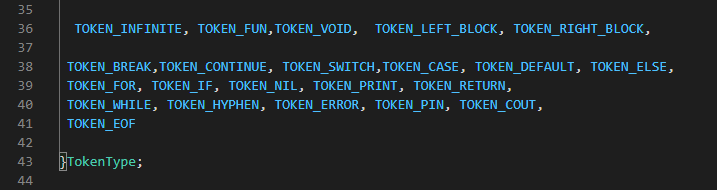
13.2 Defining list of acceptable tokens. Using an Enum called tokenType we would define a list of acceptable tokens, anything outside the list is defined as an error. We also define them in a header file since multiple files would be accessing them. In a header file called parser.h lets define the heading to avoid multi file inclusion.
The first type of token are the ones used for relational operators and comparing values, they are listed first so that their values are lower in the enum. This equally translates to their precedence, since they have the least precedence in an expression. They include : =, >, <, ==, <=, >=, &&, ||, !=.
Next the colon and tenary operator: ?, :.
The assignment operations, these operations contain ‘=’ in it. They include: -=, +=, /=, *=, ^=, |=, &=. They are the same with arithmetic operations but they are assigned the same values e.g a+=b is equivalent to a = a+b.
Next the arithmetic and logical operations: +, -, *, /, &, |, ^, <<, >>, ~.
The unary operators: ++, --, !. They have the highest precedence of all AL operations.
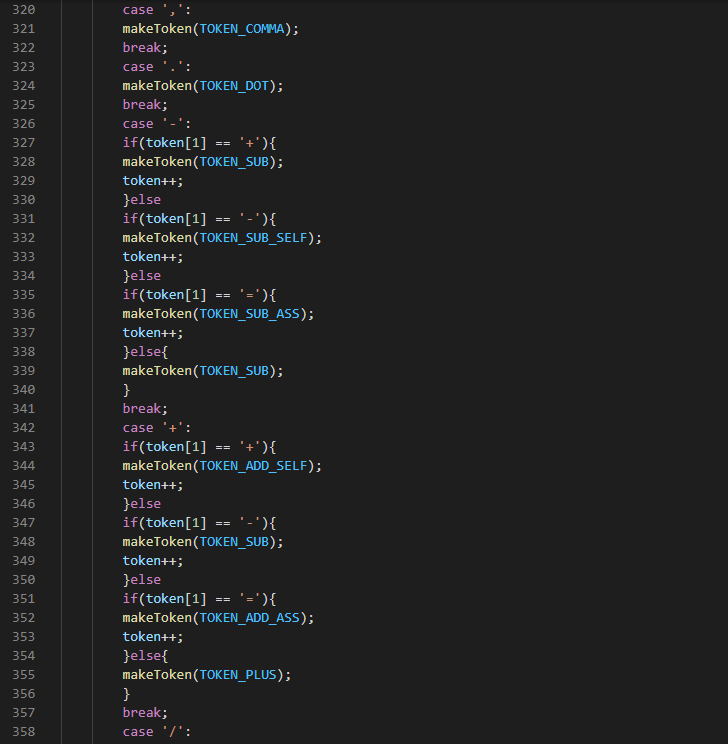
Next are grouping tokens: (,),{,}, ‘,’ ., ;
We also have intermediate tokens which are generated during compilation, they are not found within the language syntax. They include start, end, output etc.
Next are tokens used for both variable declaration and initialization.
And the rest of the tokens.which includes those used for loops eg. FOR, WHILE . conditional statement eg. IF, ELSE, CASE, SWITCH. Jump eg. BREAK, LABEL, GOTO, CONTINUE.
.
During debugging and troubleshooting , we would like to print some of the tokens. The enum class would only print out figures , so we create an array of strings containing the exact tokens placed in exactly their positions in the tokenType enum. So, that rather than print out enum which gives figures, we use the enum value as input to the array and print the token type in words.
We include the parser.h file in our token.cpp
13.3 Scanning.
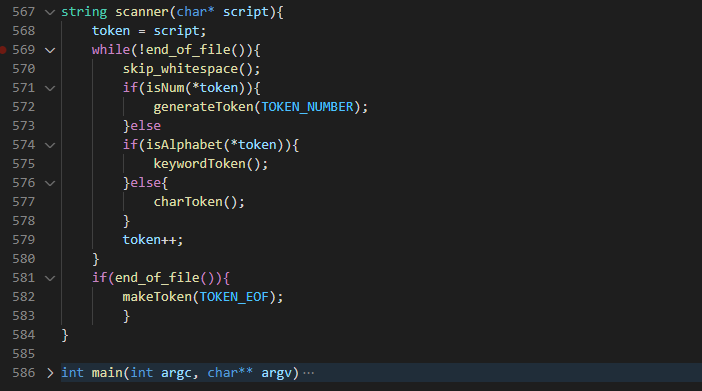
The scanner scans the written program searching for tokens. The content of the program file was copied into the scanner in section1 after we read from the file. The scanner passes the content from the argument called script to a global char* called scan which we would use throughout the token generation.
.
The scanner function is given below.
Here, the program file now contained as an argument is passed to the global char* variable called token. Using a while we will loop through the token character by character till we get to the end of the file. Using the end_of_file() function we check if there is any character left to scan. Next , using the skip_whitespace() we skip whitespaces if any exists since they are not part of our token. While the char* token contains the whole program, the *token points to a single character. Next using the isNum() function we check if the character is a number then we generate token number else using the isAlphabet() function we check for keywords, if they are no keywords then we generate strings. Finally we call charToken() to check if it is a symbols like (,),{,} etc. else then its an error . We increment the *token and start afresh until we get to the end of file. If we get to the end of file we generate the TOKEN_EOF and end the scanner.
13.4 end_of_file().
This ‘\0’ character is used to terminate string variables in cpp. The end_of_file() function returns true if the current token is equal to ‘\0’.
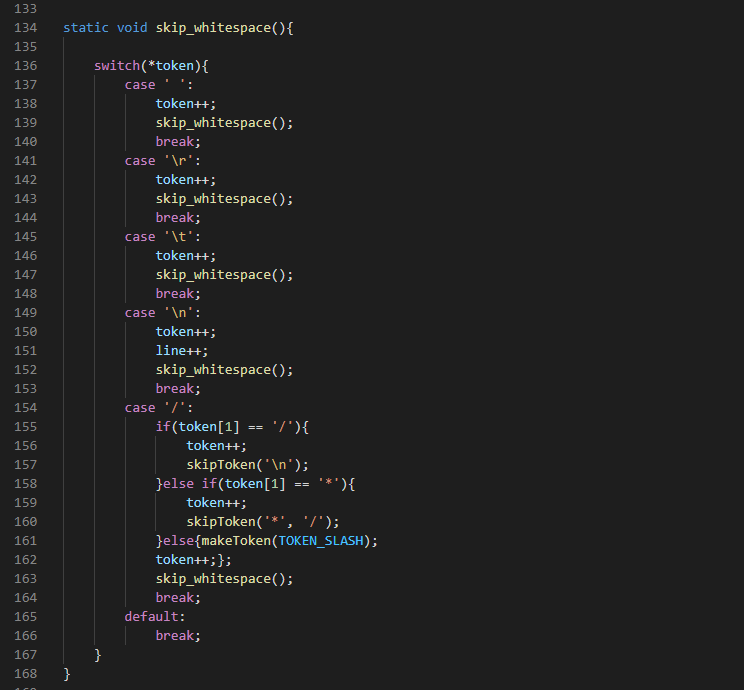
13.5 Skipwhitespace().
‘\r’, ‘\n’, ‘\t’, ‘ ’, ‘//’ are some of the tokens we search for here. We simply ignore them and skip over to the next token to do this. Using a switch statement if the current token matches any of these whitespaces we simply skip it by incrementing the token and calling the function again.
We have a global line variable which keeps track of the current line we are currently tokenizing. It starts initially at zero, and increments whenever the ‘\n’ is scanned. If the ‘/’ token is scanned we check if the next token is another ‘/’ then it is a single line comment else if the next token is ‘*’, then it is a multi line comment else it is simply a division sign then we increment and repeat the skipwhitespaces until no whitespace character is found then we exit. If it is a single line comment we skip all tokens until we meet a new line else if it is a multi line token , we skip all tokens until we meet a ‘*’ followed by ‘/’. We skip tokens using the skip_tokens() function. If it is a division token we make token slash using the makeToken() function.
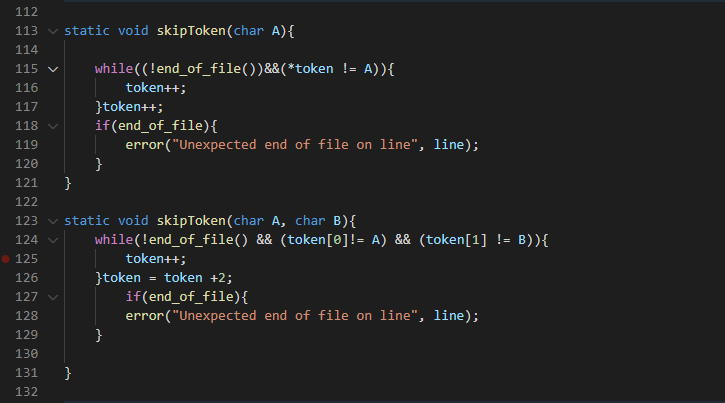
The skip_token function can either take single or two arguments. It uses a while loop to skip all tokens until the token passed in the argument is met. It also checks to make sure it is not at the end of file else it throws an "unexpected end of file error", on the current line.
13.6 isNum()
This function is used to check if a token is a number. The token is passed as an argument then using a short expression it is converted to integer . It is then compared to know if it falls between zero and nine else it is not a number.
13.7 isAlphabet()
This functions check if a token passed as an argument is an alphabet. It compares its value by checking if its value is between ‘a’ and ‘z’ or between ‘A’ and ‘Z’, else it returns false.
13.8 keywordToken()
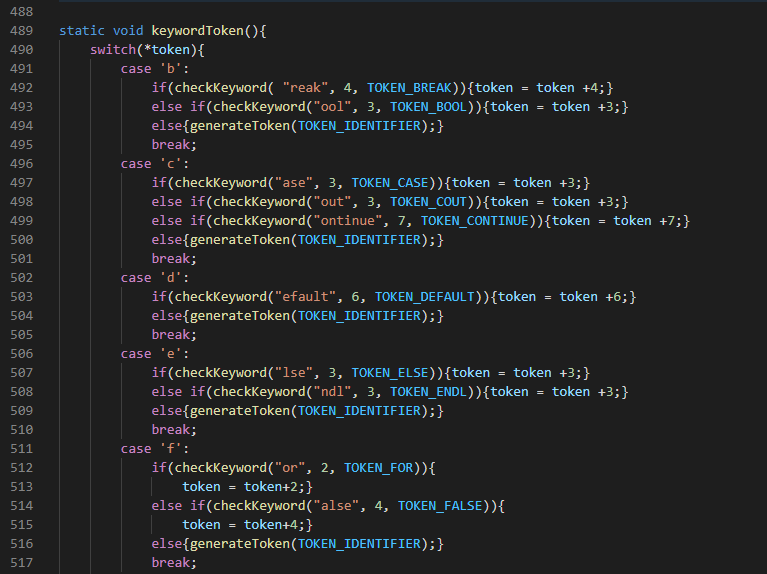
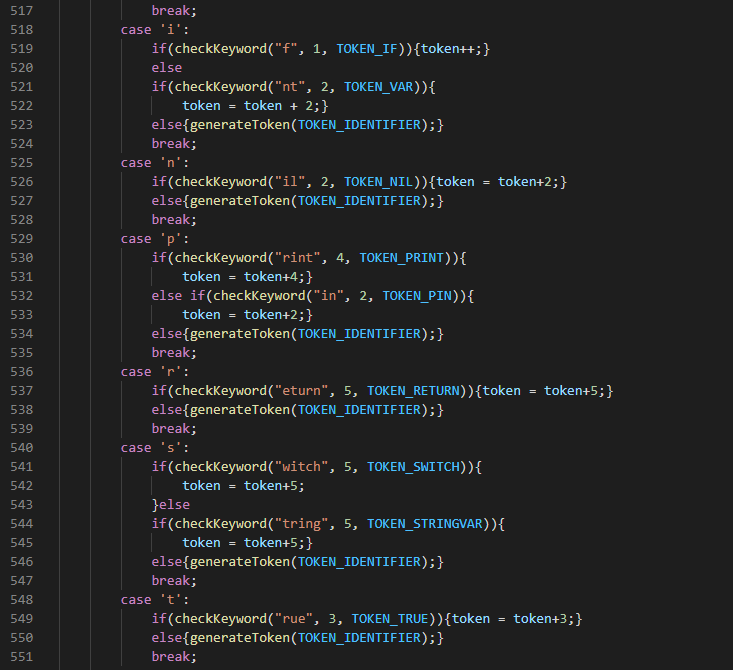
When *scan is an alphabet the keywordToken() is called. This functions compares the next series of characters in our scan to a series of keywords. If they do not match any keyword then it is an identifier. An identifier refers to any name that is not a keyword. Acceptable C++ keyword used includes: BREAK, BOOL, CASE, COUT, CONTINUE, DEFAULT, ELSE, ENDL, FOR, FALSE, IF, INT, PIN, RETURN, SWITCH, STRING, TRUE, WHILE, VOID.
This function uses a switch to compare the character with the first letter of each keyword. If anyone matches, then it uses a secondary function called checkKeyword() to compare the rest of the keyword. If the checkKeyword() returns false it will either check the next keyword that has the same first letter or generate an identifier. The checkKeyword() is a boolean function that returns true if the rest of the keyword matches the next series of characters. If it matches the checkKeyword returns true and also generates the token and our token pointer *token is incremented or shifted forward to point to the next token. The default case is to generate an identifier if none of the keyword matches.
So, for example if *token character is ‘b’. The scanner will first call the skipwhitespaces() function , then it will check if it is a number which is false, then it will call the keywordToken() function which places it in a switch. When it tests it with ‘b’, then it is a match. It will further use the checkKeyword() function like this checkKeyword(‘reak’, 4, TOKEN_BREAK). The first argument is rest of the break keyword followed by how many characters and finally the token to generate if it is a match. If it matches we skip 4 times to get to the next token to generate. 4 times here, represents skipping ‘reak’. Else if it doesn’t match then an identifier is generated.
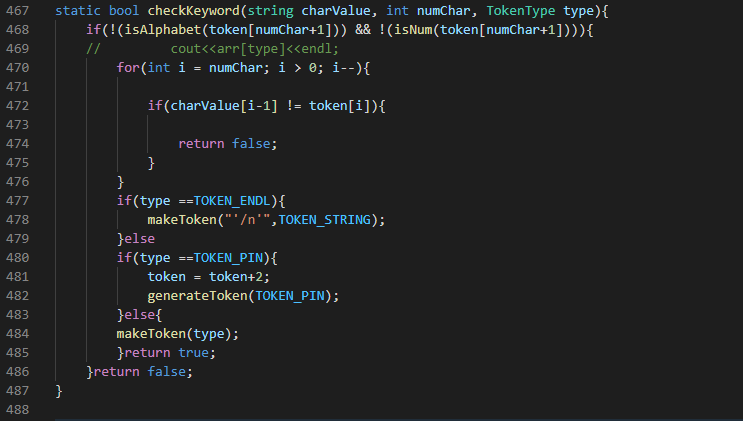
13.9 checkKeyword()
This takes three argument. The first is called string charValues which contains the series of characters to test with . int numchar which is the number of times to test , since it checks each character one after another therefore numchar stores the number of character to test. Finally is the tokentype which is the type of token to generate if the keyword matches.
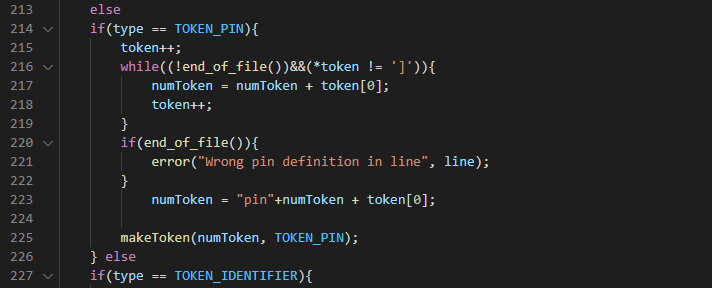
The checkKeyword() first checks that whatever comes after the keyword is neither an alphabet or a number. Example , ‘returna’, ‘return2’ are neither keywords but ‘return(’, or ‘return;’ or ‘return ’ all represent the return keyword. To do this, it takes the number of remaining character(numchar) and increments it by one to point to the next character after the keyword. If it is an alphabet or number it returns false. Next it uses a for loop which loops numChar times and compares each character in the charValue argument with the next series of characters after the current token pointer. If any of them does not match then it returns false. If all character matches it will call the makeToken() function to create the token. When the token is TOKEN_ENDL which in c++ calls a new line. We immediately translate as a new line character and generate the TOKEN_STRING instead. If it is token pin we increment our pointer by two, this moves from pointing to the pin to pointing inside the pin. Example pins are declared like this : pin[24:4], so incrementing by two moves the pointer from pointing on the ‘P’ to pointing on ‘N’, and the generateToken() is called.
13.10 charToken()
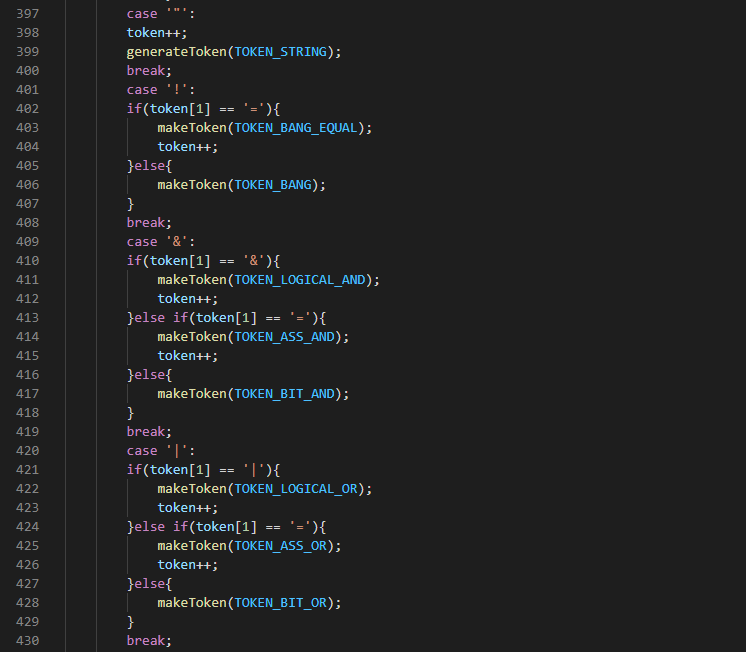
This function checks for character: <, >, ., ?, /, :, : , {,},|,\,),(,_,-,=,+,*,&,^,%, ,!. Etc. If any of the character matches it generates the equivalent token type by calling the makeToken() function. Some tokens consist of character pair example ‘--’ TOKEN_SUBSELF, ‘++’ TOKEN_ADD_SELF, >=, <=, !=, ==, +=, -=, *=, &&, ||, ;;, etc. in such a case, after checking the first character the function also checks the second character. If they do not match it ignores the compound token and treats it as a single character token. ‘;;’ which is used for an infinite loop, will generate TOKEN_INFINITE and will later be changed to TOKEN_NUMBER and given a value of ‘1’. Since 1 in a loop is same as infinite loop. ‘"’ matches the beginning of a string , rather than makeToken TOKEN_COMMA we use the generateToken TOKEN_STRING.
Two global parameters: braceCount and parenCount are used to keep track of braces and parenthesis. They are used for error check in the checkField() function. When the character is a left brace or left parenthesis the braceCount or parenCount is incremented respectively and when the character is a right brace or right parenthesis then the braceCount or parenCount is decremented respectively.
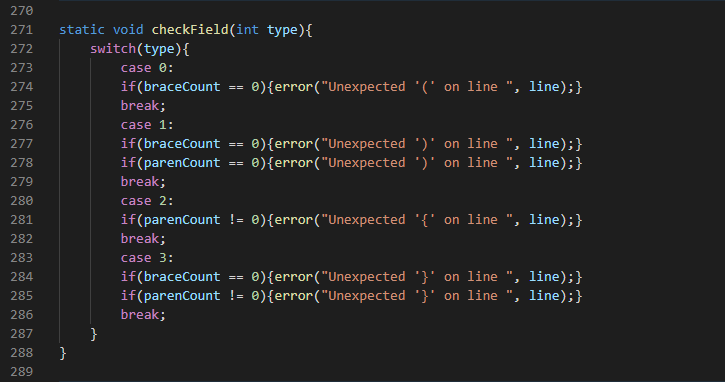
13.11 checkField()
The checkField() function is called within the charToken() function. If the character is ‘(’, it calls the checkField() with an argument of ‘0’. This makes sure that the braceCount is not equal to zero. i.e All left parenthesis must be declared within atleast one open brace which is the function opening brace. If the character is ‘)’, then it calls the checkField() with an argument of 1. Added with the condition already stated it also makes sure that the parenCount is not equal to zero. i.e. All right parenthesis must be declared within atleast after one left parenthesis. Since ‘)’ represents a closing parenthesis then it expects to have a corresponding opening parenthesis. If the character is ‘{’, then it calls checkField() with an argument of 2. Since it is an opening brace it only checks to make sure that parenCount is equal to zero. i.e every parenthesis must be closed before an opening brace. If the character is ‘}’, then it calls checkField() with an argument of 3. Along side the condition given for opening brace, it also checks to make sure that a brace is actually open before closing one i.e braceCount is not zero.
13.12 generateToken()
The generateToken() function is an intermediate used to make tokens. It process tokens that store data before calling makeToken(). e.g TOKEN_NUMBER, TOKEN_STRING, TOKEN_PIN, TOKEN_IDENTIFIER all store data while TOKEN_LEFT_PAREN etc. does not store data. An empty string called numToken is used to hold the data . If the character is number then the generateToken(TOKEN_NUMBER) is called. Then using a while loop it loops through the next character while incrementing it till it reaches the end of file or the next character is no longer a number. Each number character is accumulated in the numToken string and the makeToken() is called. If it meets the end of file then it throws an error.
If the character is an infinite character i.e ‘;;’. Then it simply calls the makeToken to generate TOKEN_NUMBER while passing ‘1’ as the numToken. ‘1’ in a loop represents an infinite loop.
When the character is a double quote, the generateToken() generates a string. By accumulating the numToken with next character in our *token until it meets EOF or a closing double quotes. If it meets a double quotes then it calls the makeToken(), else if it meets EOF , it throws an error.
If the characters is ‘pin’, it also loops until EOF or a terminating block quote. Pin are declared in this form: pin[12:6]. It adds the keyword ‘pin’ before makeToken.
If the character is an alphabet. It loops through the keyword() switch if it does not match any keyword then TOKEN_IDENTIFIER is generated. It continuously loops until it no longer expects an alphabet, underscore or a number.
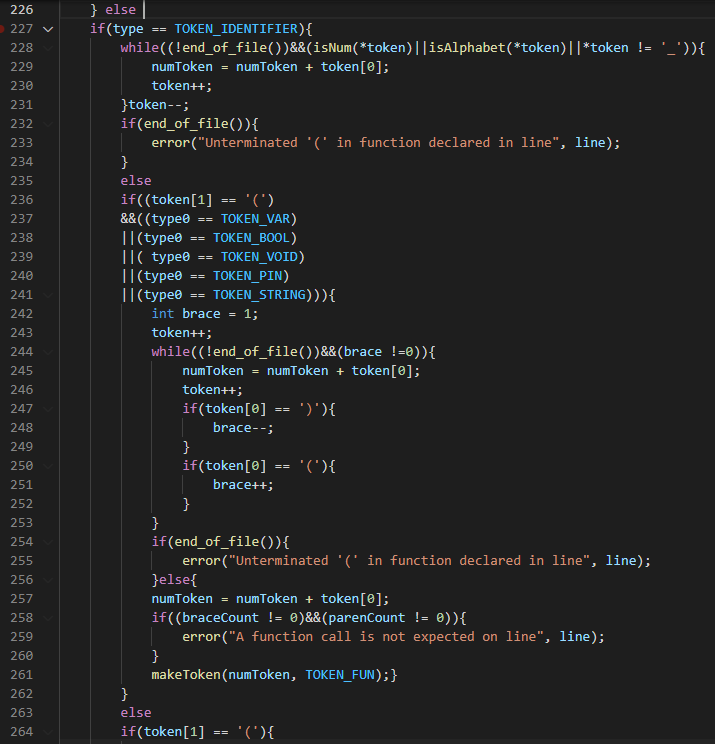
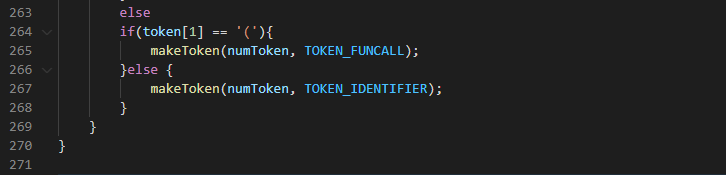
If it meets an EOF then it throws an error else it checks if the identifier is a function name during declaration or a function name when it is being called. The two are different because they are processed differently as we would soon see. To differentiate both, it uses the variable ‘Type0’ which records the previous token. Therefore if it is an identifier and the next character is a ‘(’ then it is certainly a function. Also if type0 is either int, void, bool, etc. then it is a function declaration. It will therefore, continue to accumulate the function argument until it meets the closing brace. If it meets an EOF then it throws an error.It also makes sure that the parenCount and braceCount are both zero by checking their values and throwing an error. Else if it is not a function declaration , and it expects a ‘(’ then it is a function call else it just an identifier.
13.13 writeToFile()
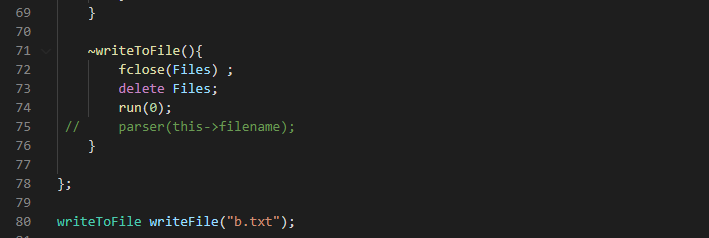
Before we discuss the makeToken(). Lets talk about writetoFile() function. The makeToken sends the tokens to a function in another file , the parser. We discuss that later, it also copies it to a file for debugging and for processing using other methods. This new file is defined in a class called writeToFile().
This class has one function, one constructor and one destructor. The constructor takes as argument a file name called codefile and passed to its public variable called filename. It calculates the size into variable n. It creates an array of equal size called char_array and using strcpy(), it opens it in write mode. Here, all the tokens are copied into it.
The destructor closes the file, and calls run(). This function initiates the parser.
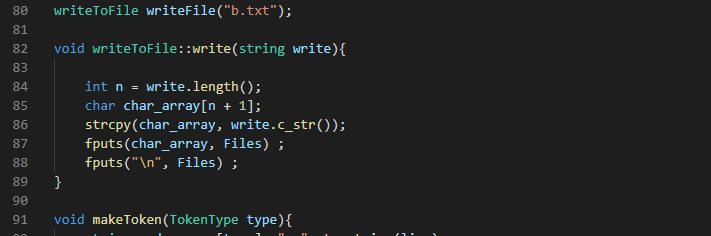
The constructor is called here.
The class has only one function write(). This function writes token data into the file. The token data is passed as an argument into the string write . The size is calculated and a char of equal size is created to hold the data using strcpy(). Finally using Fputs(), the data is copied into the file. A new line is also added to begin the next token on a new line.
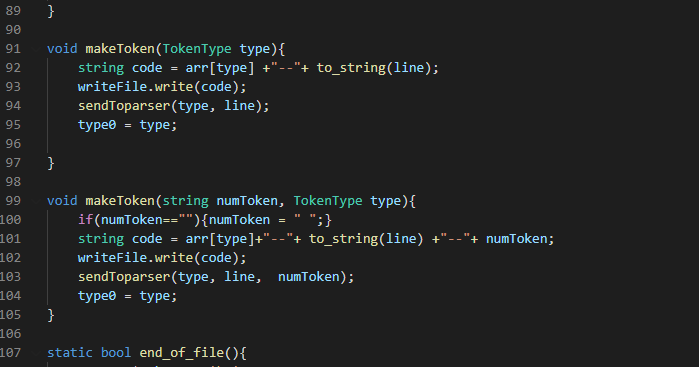
13.14 makeToken()
This function generates the tokens , sends them to the parser and also calls the write() function to copy tokens to the file. Thanks to polymorphism it can process tokens with data differently from those without any data. It takes as an argument the token type and the data for tokens that contain data. Using the string code, it merges the token type, line number and numToken data together in one string. The arr[] translates the toens from their enum numbers to string. Then it writes the value to the open file and also using the sendToparser() function , it sends it to the parser. Finally it stores the token as type0 which represents the previous token used to differentiate between function declaration and function call.





















 The checkKeyword() first checks that whatever comes after the keyword is neither an alphabet or a number. Example , ‘returna’, ‘return2’ are neither keywords but ‘return(’, or ‘return;’ or ‘return ’ all represent the return keyword. To do this, it takes the number of remaining character(numchar) and increments it by one to point to the next character after the keyword. If it is an alphabet or number it returns false. Next it uses a for loop which loops
The checkKeyword() first checks that whatever comes after the keyword is neither an alphabet or a number. Example , ‘returna’, ‘return2’ are neither keywords but ‘return(’, or ‘return;’ or ‘return ’ all represent the return keyword. To do this, it takes the number of remaining character(numchar) and increments it by one to point to the next character after the keyword. If it is an alphabet or number it returns false. Next it uses a for loop which loops